L’actualité du jour apporte un éclairage intéressant sur l’évolution du domaine.
Découvrez MemPrivacy : une infrastructure « edge-cloud » qui utilise la pseudonymisation réversible locale pour protéger les données des usagers sans nuire à l’efficacité de la mémoire
À mesure que les agents basés sur les modèles de langage (LLM) passent de la phase de recherche à celle de la mise en production, un dilemme de conception devient de plus en plus difficile à ignorer : plus la mémoire hébergée dans le cloud gagne en utilité, plus elle expose les données privées des utilisateurs. Des chercheurs de MemTensor (Shanghai), de HONOR Device et de l’université de Tongji ont présenté MemPrivacy, un cadre visant à résoudre ce dilemme sans pour autant sacrifier l’utilité qui fait tout l’intérêt de la mémoire personnalisée.
Lorsque vous interagissez avec un agent IA, votre conversation contient souvent des informations sensibles telles que des données médicales, des adresses e-mail, des données financières, des mots de passe, etc. Dans un déploiement edge-cloud classique, l’appareil de l’utilisateur (la périphérie) gère les entrées, tandis que la gestion de la mémoire et le raisonnement, qui nécessitent une grande puissance de calcul, s’effectuent dans le cloud. Cette architecture est performante, toutefois elle implique que les données brutes et non filtrées de l’utilisateur soient transmises vers les systèmes cloud et y soient conservées.
L’utilisateur obtient par conséquent une réponse parfaitement cohérente et personnalisée.
Le risque n’est pas purement théorique. Des études antérieures montrent que les attaques par mémoire à plusieurs étapes peuvent entraîner des atteintes à la vie privée avec des taux de réussite pouvant atteindre 69 %, et que les attaques par fuite de données visant les systèmes de mémoire peuvent atteindre un taux de réussite de 75 %. L’injection indirecte de messages peut même amener les agents à soutirer activement des informations privées aux utilisateurs. Une fois que des données sensibles ont été enregistrées dans des journaux cloud, des bases de données vectorielles ou des systèmes de stockage externes, elles peuvent rester accessibles tout au long des étapes ultérieures de stockage, de récupération et de réutilisation, bien au-delà de l’interaction initiale.
Des travaux antérieurs ont tenté de résoudre ce problème par le masquage, c’est-à-dire en remplaçant les informations sensibles par des caractères génériques tels que ***. Le problème est que le masquage altère le sens. Si un utilisateur demande à un agent de rédiger un e-mail destiné à un médecin et que sa tension artérielle ainsi que son adresse e-mail sont toutes deux remplacées par ***, le modèle cloud ne peut pas accomplir cette tâche de manière pertinente. Des techniques plus rigoureuses, telles que la confidentialité différentielle et la protection cryptographique, offrent des garanties plus solides, mais sont difficiles à intégrer dans les pipelines de mémoire interactifs sans nuire à la qualité de la réponse.
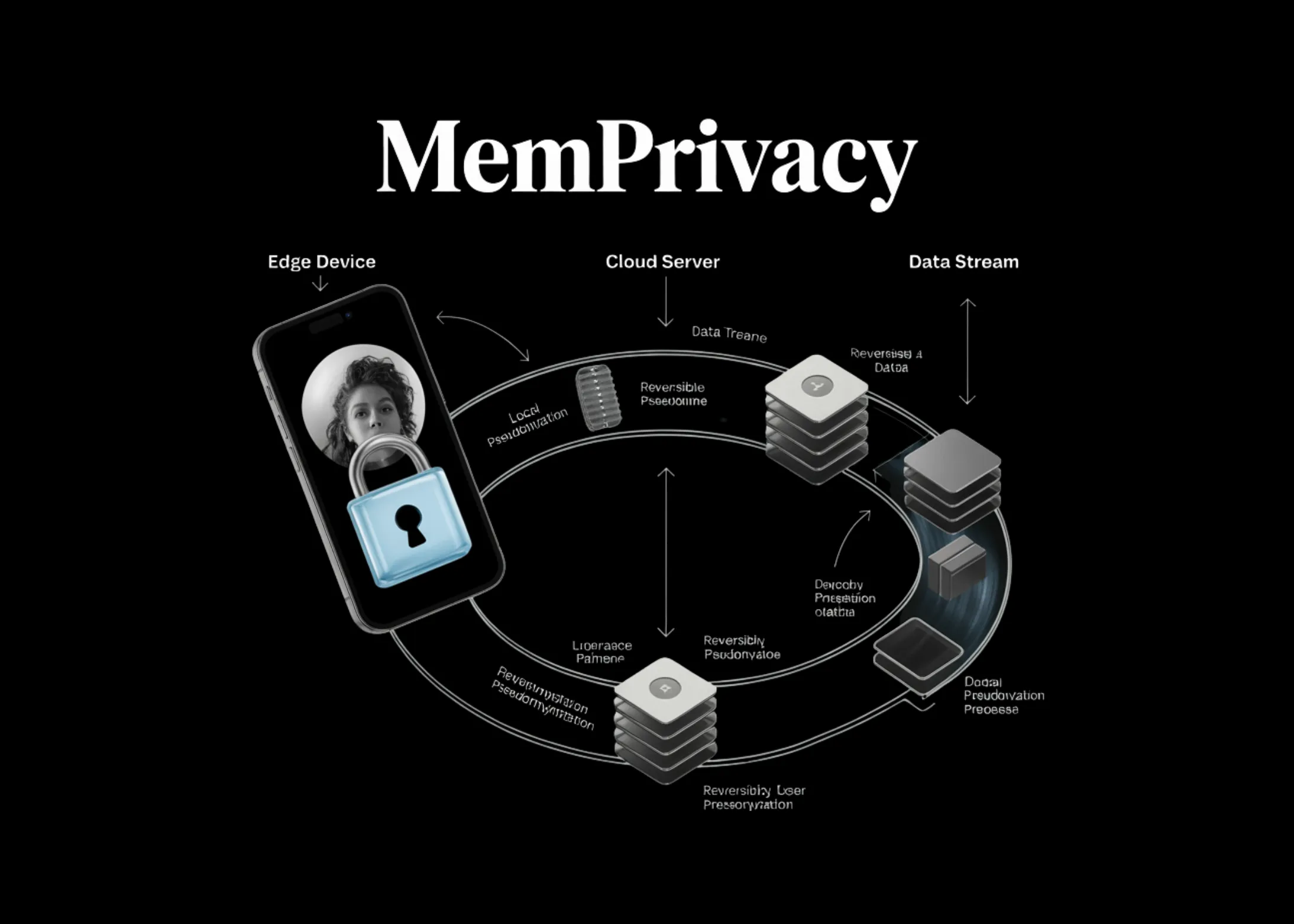
Au lieu de masquer les données confidentielles, MemPrivacy les remplace par des marqueurs de place—des jetons structurés tels que
De plus, cette approche, appelée « pseudonymisation réversible locale », s’articule en trois étapes. Étape 1 (désensibilisation en amont) : un système léger intégré à l’appareil identifie les segments sensibles en matière de confidentialité dans les données d’entrée, les classe par type et par niveau de sensibilité, puis les remplace par des espaces réservés typés. Les correspondances entre les valeurs d’origine et les espaces réservés sont stockées localement et conservées d’une session à l’autre, de sorte que la même valeur soit toujours associée au même espace réservé. Étape 2 (traitement dans le cloud) : les données d’entrée nettoyées sont envoyées à l’agent cloud ou au dispositif de mémoire. Les espaces réservés typés conservent une structure sémantique suffisante pour permettre le bon fonctionnement des processus de formation et de récupération de la mémoire. Étape 3 (restauration de la liaison descendante) : la réponse du cloud, qui peut contenir des espaces réservés, est restaurée localement par le biais d’une consultation de base de données allégée et d’une substitution de chaînes de caractères, ce qui n’ajoute qu’une latence négligeable.
L’une des principales contributions de l’équipe de travaux de recherche est une taxonomie de la vie privée à quatre niveaux (PL1–PL4) qui définit ce qui est protégé et à partir de quel seuil :
Il faudra attendre les retours concrets pour juger de l’impact réel.
Dans le même ordre d’idées :
- Comment créer un système d’IA agentique avancé doté de capacités de planification, d’appel d’outils, de mémoire et d’autocritique à l’aide de l’API OpenAI
- La refonte de Siri par Apple pourrait inclure la suppression automatique des conversations | TechCrunch
- Assurer la souveraineté en matière d’IA et de données à l’ère des systèmes autonomes
Article original publié par MarkTechPost : MarkTechPost