L’industrie de l’IA poursuit sa transformation rapide avec cette nouvelle annonce.
Combler le « fossé de l’expressivité » : comment la technologie Voxtral TTS de Mistral redéfinit le clonage vocal multilingue grâce à une architecture hybride alliant régression automatique et adaptation du flux
L’IA vocale cache un secret inavouable. La plupart des systèmes de synthèse vocale semblent fonctionner correctement… jusqu’à ce qu’ils ne le fassent plus. Ils sont capables de lire une phrase, toutefois ils ne parviennent pas à lui donner de la vie. Le rythme est décalé. L’émotion est plate. La voix ressemble à celle d’une personne réelle pendant deux secondes, puis bascule dans un registre synthétique et générique. Cet écart entre un son intelligible et une parole véritablement expressive, fidèle à la voix de l’orateur, est ce que nous appelons le « fossé de l’expressivité » — et il constitue le principal obstacle pour tous les programmeurs qui tentent de créer des assistants vocaux, des chaînes de production de livres audio ou des systèmes d’assistance client multilingues capables de résister à l’examen minutieux des utilisateurs.
La nouvelle version de Mistral AI, Voxtral TTS, vise précisément à combler cette lacune. Il s’agit du premier modèle de synthèse vocale de Mistral, publié simultanément sous forme de poids ouverts sur Hugging Face et d’API, et il repose sur un choix architectural audacieux : utiliser deux paradigmes de modélisation totalement distincts — la génération autorégressive et l’adaptation de flux — pour les deux problèmes fondamentalement différents que pose le clonage vocal.
Précisons, le résultat est un système totalisant environ 4 milliards de paramètres — un cœur de décodeur de 3,4 milliards de paramètres, un transformateur acoustique de correspondance de flux de 390 millions de paramètres et un codec audio neuronal de 300 millions de paramètres — qui génère une parole naturelle et fidèle à l’orateur dans 9 langues à partir d’à peine 3 secondes d’audio de référence, atteint un taux de réussite de 68,4 % par rapport à ElevenLabs Flash v2.5 lors d’évaluations de clonage vocal multilingue menées par des annotateurs locuteurs natifs, et dessert plus de 30 utilisateurs simultanés à partir d’une seule carte NVIDIA H200 avec une latence inférieure à 600 ms.
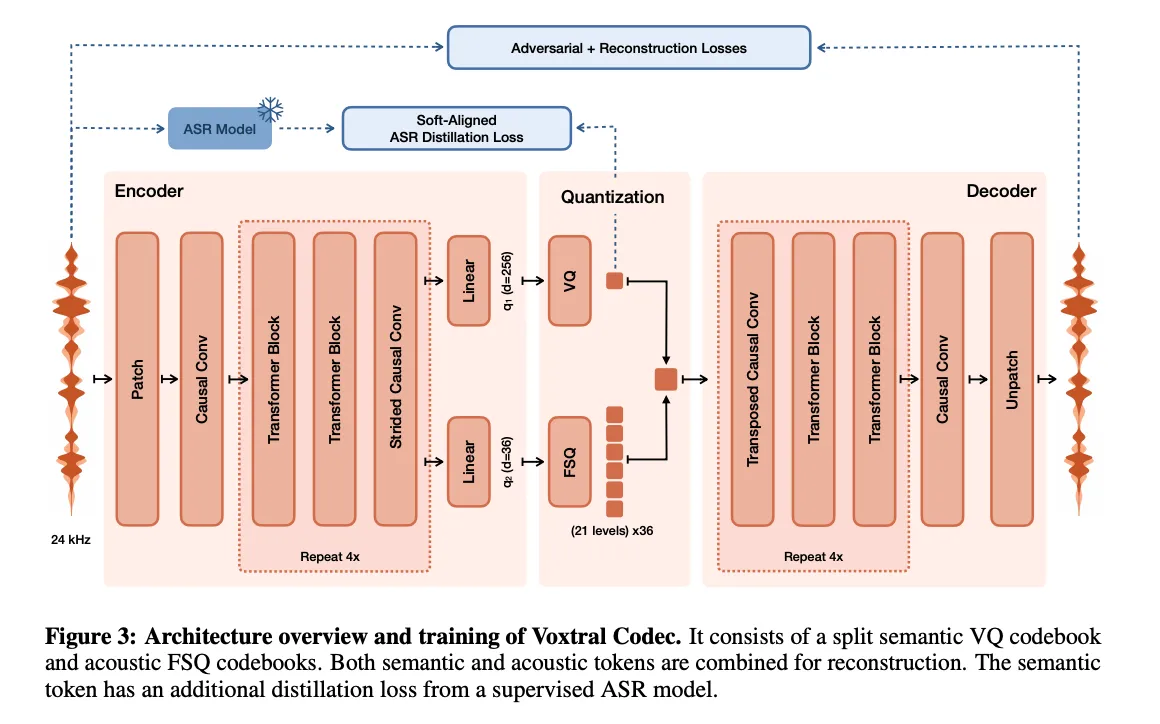
Point notable, considérez la parole comme deux signaux totalement distincts qui se propagent sous la même forme d’onde. Il y a la couche sémantique — les mots, la grammaire, la structure linguistique. Et il y a la couche acoustique — l’identité de l’orateur, son registre émotionnel, sa prosodie et son rythme.
Précisons, ces deux niveaux présentent des propriétés statistiques fondamentalement différentes, et le fait d’imposer une seule approche de modélisation pour les traiter simultanément oblige à faire un compromis difficile. Les modèles autorégressifs excellent en matière de cohérence à long terme — ils permettent à un locuteur de conserver son style tout au long d’un paragraphe — mais ils sont lents et coûteux lorsqu’ils sont appliqués aux 36 tokens du livre de codes acoustiques qui définissent la texture audio fine à chaque image. Les modèles basés sur le flux excellent dans la génération de variations acoustiques riches et continues, mais ils ne disposent pas de la mémoire séquentielle qui permet à un locuteur de s’exprimer de manière cohérente au fil du temps.
À ce sujet, voxtral TTS s’articule autour de trois composants qui fonctionnent de concert au sein d’un pipeline de bout en bout unique.
Après un pré-entraînement sur des paires de fichiers audio et de transcriptions, le système de synthèse vocale Voxtral est soumis à un post-entraînement à l’aide de l’optimisation directe des préférences (DPO). Les tokens acoustiques utilisant une correspondance de flux plutôt qu’une tête discrète standard, l’équipe de travaux de recherche a adapté un objectif DPO basé sur le flux, en plus de la perte DPO standard pour le livre de codes sémantique.
Les paires d’échantillons « gagnant-perdant » sont constituées à partir du taux d’erreurs sur les mots (WER), des scores de similarité entre locuteurs, de la cohérence du volume sonore, de l’UTMOS-v2 et des mesures des juges LM. Conclusion principale : un entraînement de plus d’une époque sur des données DPO synthétiques rend le modèle plus robotique, et non l’inverse. Une époque constitue le juste milieu.
Cette nouvelle étape pose plusieurs questions qui restent ouvertes.
Sur le même sujet :
- Inworld AI lance Realtime TTS-2 : un système vocal en boucle fermée qui s’adapte à votre façon de parler
- Comment OpenAI propose une IA vocale à faible latence à grande échelle
- Le Pentagone conclut des accords classifiés en matière d’IA avec OpenAI, Google et Nvidia – mais pas avec Anthropic
D’après MarkTechPost : MarkTechPost