Le secteur technologique continue de livrer des avancées remarquables.
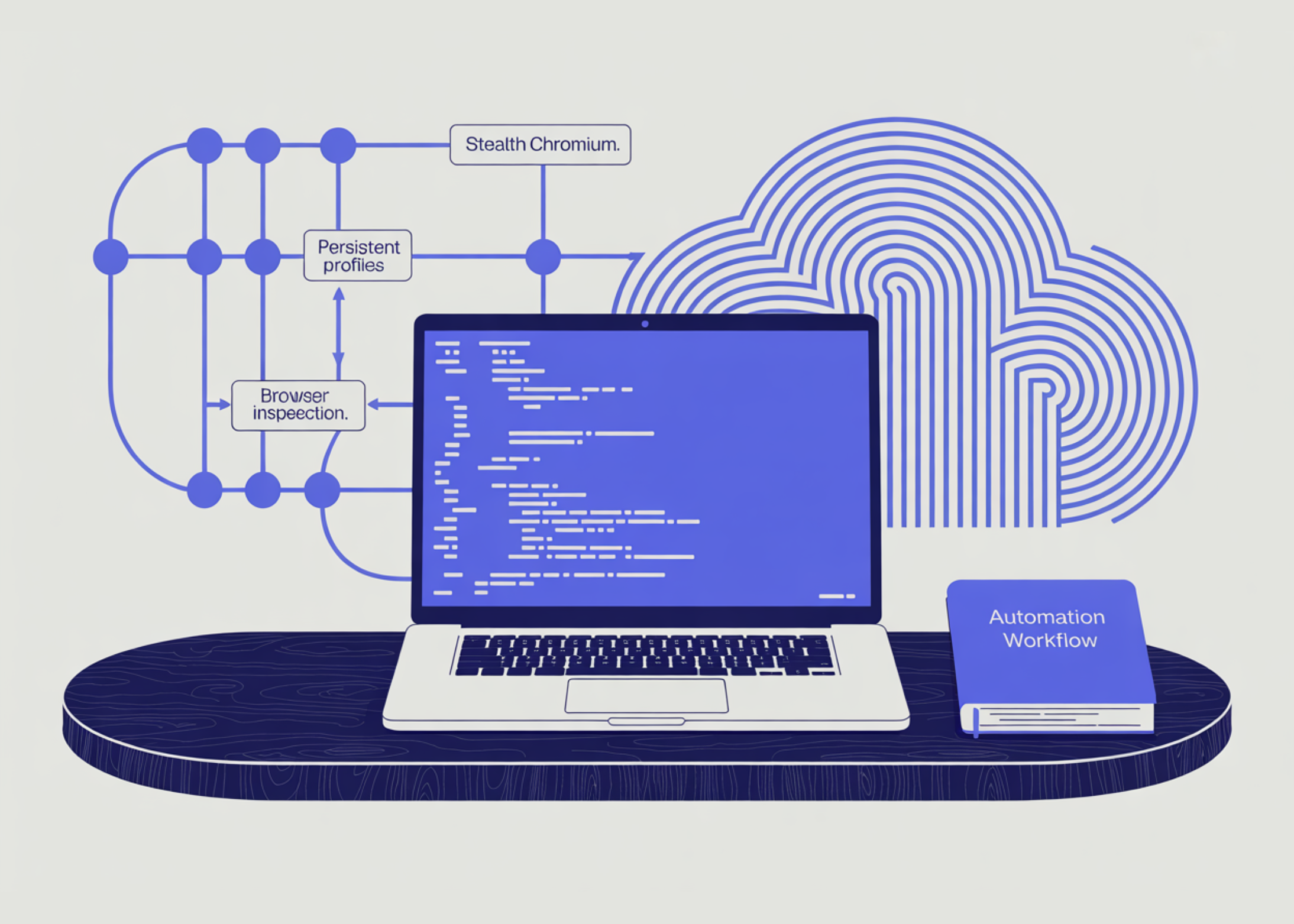
Créer un workflow d’automatisation CloakBrowser à l’aide de Stealth Chromium, de profils persistants et de l’analyse des signaux du navigateur
Dans ce tutoriel, nous allons découvrir CloakBrowser, un solution d’automatisation de navigateur compatible avec Python qui utilise des API de type Playwright au sein d’un environnement Chromium furtif. Nous commençons par configurer CloakBrowser, en préparant le fichier binaire du navigateur requis, puis nous résolvons le problème courant lié à la boucle asyncio de Colab en exécutant le workflow de synchronisation du navigateur dans un thread de travail distinct. Nous abordons ensuite les étapes pratiques de l’automatisation, notamment le lancement d’un navigateur, la création de contextes de navigateur personnalisés, l’analyse des signaux visibles par le navigateur, l’interaction avec une page de test locale, l’enregistrement de l’état de la session, la restauration du localStorage, l’utilisation de profils de navigateur persistants, la capture de captures d’écran et l’extraction du contenu de la page affichée à des fins d’analyse.
Nous commençons par installer CloakBrowser, Playwright, pandas et BeautifulSoup afin que l’environnement Colab dispose de tout le nécessaire pour l’automatisation du navigateur et l’analyse des résultats. Nous installons également les dépendances d’exécution de Chromium, importons les principaux utilitaires de introduction de CloakBrowser et définissons les chemins d’accès pour les captures d’écran, l’état de stockage et les profils persistants. Nous préparons ensuite le binaire CloakBrowser et affichons ses détails afin de vérifier que le moteur de navigation est correctement installé avant de lancer l’automatisation.
Nous terminons en affichant le message de fin du tutoriel et en répertoriant tous les fichiers créés dans le répertoire de travail.
Notons par ailleurs, nous définissons des fonctions d’aide pour créer des URL de données, afficher les en-têtes de section, fermer en toute sécurité les objets du navigateur et exécuter des tâches synchrones du navigateur dans un thread distinct. Nous utilisons le wrapper de thread car Google Colab exécute déjà une boucle asyncio, ce qui évite que l’API synchrone de Playwright ne rencontre des problèmes. Nous créons également une page de test HTML locale sécurisée qui recueille les signaux visibles par le navigateur, prend en charge l’interaction avec les formulaires et stocke les valeurs de test dans localStorage.
En complément, nous définissons la tâche principale du tutoriel et commençons par lancer CloakBrowser en mode sans interface graphique afin d’ouvrir une page publique simple et d’en extraire le titre, l’aperçu du corps du texte et l’URL. Nous créons ensuite un contexte de navigation personnalisé avec une fenêtre d’affichage, des paramètres régionaux, un fuseau horaire, une palette de couleurs et des en-têtes personnalisés afin de simuler une session de navigation mieux contrôlée. Nous interagissons avec le formulaire de test local, recueillons les signaux du navigateur, enregistrons une capture d’écran, conservons l’état de la session, puis vérifions si le contenu de localStorage peut être restauré dans un nouveau contexte.
Notons par ailleurs, nous poursuivons ce tutoriel en créant un répertoire de profil de navigateur persistant et en l’utilisant pour enregistrer des données dans localStorage, même après le redémarrage du navigateur. Nous lançons le profil persistant à deux reprises : d’abord pour y enregistrer une valeur, puis pour vérifier que cette valeur est toujours présente lors du deuxième mise en service. Nous avons en outre montré comment afficher une page en temps réel et extraire la page affichée, puis analyser le code HTML renvoyé par le navigateur à l’aide de BeautifulSoup afin d’analyser le contenu statique.
Notons par ailleurs, nous exécutons l’intégralité du tutoriel CloakBrowser au sein d’un conteneur de thread sécurisé. Nous affichons la capture d’écran et générons un tableau récapitulatif structuré dans pandas contenant les signaux du navigateur, les résultats de la persistance, les données de navigation, les performances de l’extraction, les chemins d’accès des fichiers générés et les éventuelles erreurs. Nous terminons en affichant le message de fin du tutoriel et en répertoriant tous les fichiers créés dans le répertoire de travail.
Les retombées concrètes se feront sentir dans les mois qui viennent.
À lire également :
- TSMC mise sur l’énergie éolienne alors que la demande en puces IA explose et que Taïwan est confrontée à une pénurie d’énergie
- Le plus fervent partisan de Musk est devenu son plus grand handicap
Via MarkTechPost : MarkTechPost