Un nouveau jalon vient d’être franchi dans l’univers de l’intelligence artificielle.
NVIDIA AI lance Nemotron 3 Ultra : un modèle hybride Mamba-Transformer « Mixture-of-Experts » ouvert de 550 milliards de paramètres, destiné aux agents à exécution longue
NVIDIA a lancé Nemotron 3 Ultra, le plus grand modèle de sa gamme Nemotron 3. Il vise à résoudre un problème spécifique : celui des agents à exécution longue qui planifient, invoquent des outils et raisonnent sur plusieurs tours. À mesure que les agents s’exécutent plus longtemps, le nombre de tokens augmente et le coût de l’inférence grimpe. Nemotron 3 Ultra est conçu pour maintenir un haut niveau de précision tout en rendant cette inférence plus rapide et moins coûteuse.
Nemotron 3 Ultra est un modèle de type « Mixture-of-Experts » (MoE) comptant au total 550 milliards de paramètres. Seuls 55 milliards de paramètres sont actifs par token. La conception MoE améliore la précision par paramètre actif.
Il utilise une architecture hybride Mamba-Attention plutôt qu’un Transformer pur. Les couches Mamba traitent les longues séquences avec une complexité subquadratique. Quelques couches Attention sont conservées pour garantir une précision de rappel optimale sur des contextes étendus.
Le modèle a été pré-entraîné sur 20 000 milliards de tokens textuels. Le contexte a ensuite été étendu à 1 million de tokens. Il a ensuite été post-entraîné à l’aide du « Supervised Fine-Tuning » (SFT), de l’apprentissage par renforcement (RL) et de la « Multi-teacher On-Policy Distillation » (MOPD).
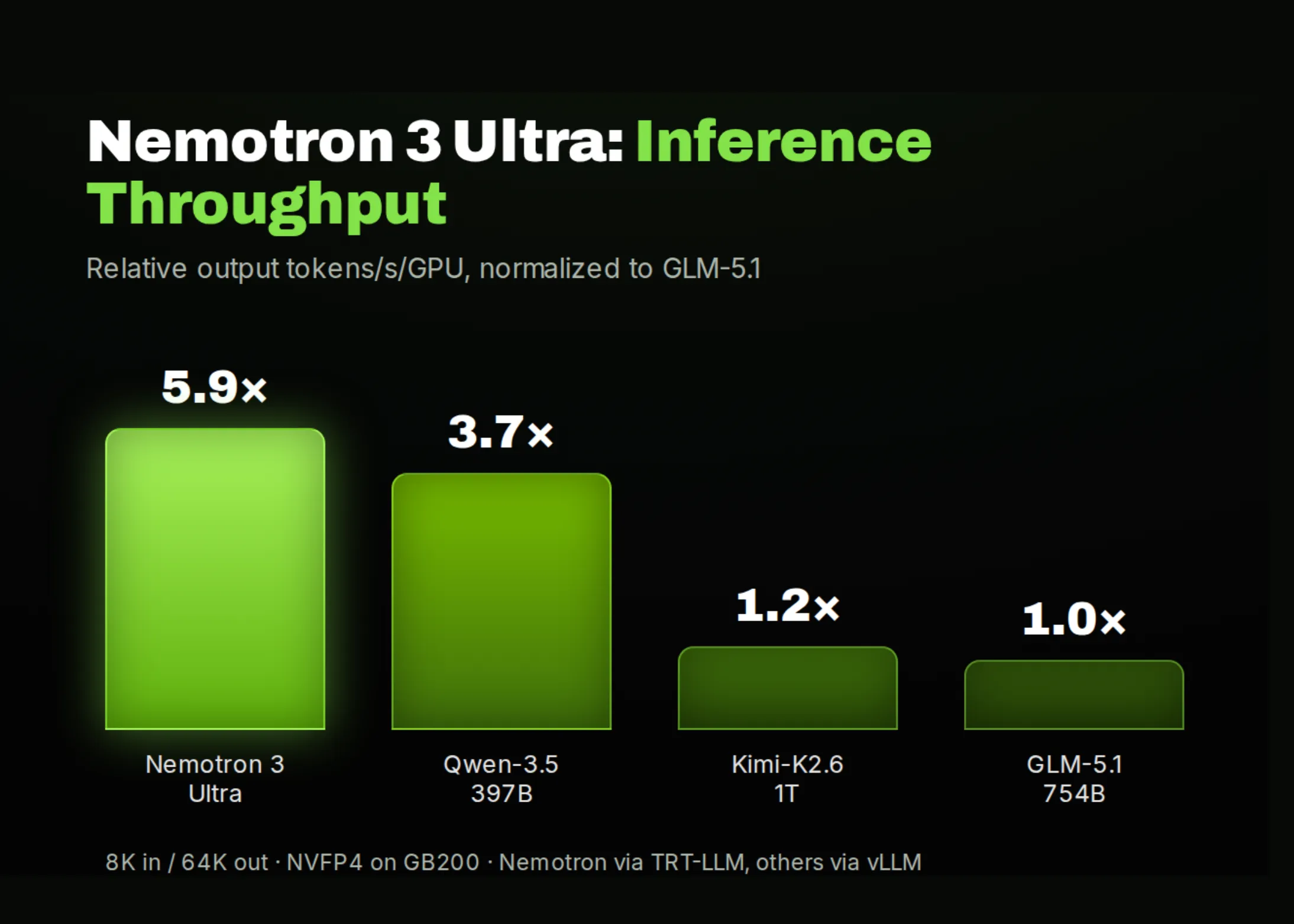
En parallèle, l’équipe NVIDIA annonce un débit d’inférence jusqu’à environ six fois supérieur à celui de modèles de langage de grande envergure (LLM) ouverts comparables, tout en conservant une précision équivalente.
À noter également, le modèle comporte 108 couches et présente une dimension de 8 192. Il utilise 64 têtes de requête et seulement 2 têtes clé-valeur, ce qui permet de limiter la taille du cache KV. Chaque couche MoE contient 512 experts, dont les 22 premiers sont activés par token.
Les grandes lignes :
- Le modèle a été pré-entraîné sur 20 000 milliards de tokens textuels.
- Le modèle comporte 108 couches et présente une dimension de 8 192.
Difficile à ce stade de prédire tous les impacts de cette annonce.
Sur le même sujet :
- Ces grands modèles de langage (LLM) sont les plus efficaces pour contrer la propagande russe
- Découvrez OpenJarvis : un framework axé sur le local pour les agents IA personnels embarqués, doté d’outils, d’une mémoire et de capacités d’apprentissage
- Codex pour chaque rôle, outil et flux de travail
Source originale : MarkTechPost : MarkTechPost