Le paysage de l’intelligence artificielle s’enrichit d’une nouveauté significative.
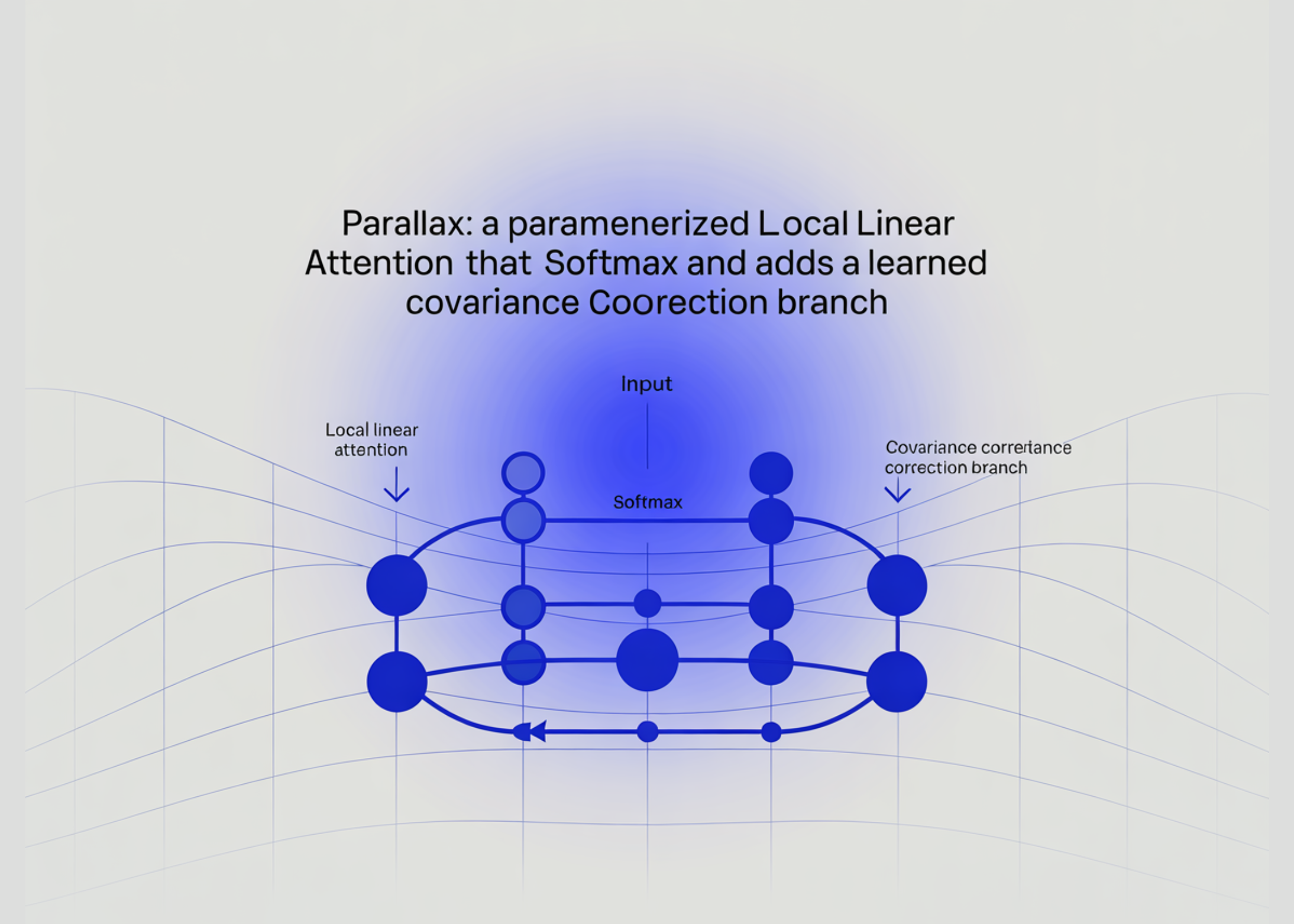
Parallaxe : une attention linéaire locale paramétrée qui conserve Softmax et ajoute une branche de correction de covariance apprise
Le mécanisme d’attention du Transformer a à peine changé depuis 2017. La plupart des travaux d’efficacité ont tenté de remplacer purement et simplement l’attention softmax. Un tout nouveau journal emprunte un chemin différent. Il garde l’attention du softmax et se boulonne sur une branche de correction.
Une équipe de chercheurs de l’Université Northwestern, de Tilde Research et de l’Université de Washington présente une attention linéaire locale paramétrée appelée « Parallax » qui s’adapte au pré-entraînement LLM et aux conceptions de code avec Muon.
Parallax ne recherche pas l’efficacité en supprimant le calcul. Il ajoute délibérément du calcul, puis rend ce calcul moins cher à exécuter sur des GPU modernes.
Parallax s’appuie sur l’attention linéaire locale (LLA). LLA vient du cadre de régression au temps de test. Ce cadre lit l’attention comme un solveur de régression sur des paires clé-valeur.
Dans cette vue, les clés sont des points de éléments d’entraînement. Les valeurs sont des étiquettes. La requête est le point de test. Attention Softmax est un estimateur non paramétrique appelé Nadaraya-Watson. Il correspond à une fonction constante locale pour chaque requête.
Dans le même temps, lLA met à niveau cette estimation constante locale en une estimation linéaire locale. L’équipe de travaux de recherche prouve que cela donne une erreur quadratique moyenne intégrée strictement plus petite. L’avantage réside dans de meilleurs compromis biais-variance pour la mémoire associative.
Toutefois LLA a un problème à grande échelle. Son avancement exact nécessite la résolution d’un système linéaire pour chaque requête. Cela utilise un solveur de gradient conjugué parallèle (CG). Le solveur CG crée trois problèmes : des E/S intensives, un compromis difficile entre régularisation et expressivité et une incompatibilité de faible précision.
Parallax supprime le solveur. Au lieu de cela, il apprend une matrice de projection supplémentaire. L’équipe de exploration écrit cela sous la forme ρi= WRxi. Ici, WR est une matrice apprenable qui sonde la covariance KV directement à partir de l’entrée de la couche.
L’évolution de ce dossier sera à suivre avec attention.
Dans le même ordre d’idées :
Lire l’article complet sur MarkTechPost : MarkTechPost