Les développements se succèdent à un rythme impressionnant dans l’IA.
Mettre en place un pipeline complet d’observabilité et d’évaluation Langfuse pour le traçage, la gestion des invites, l’évaluation et les expériences
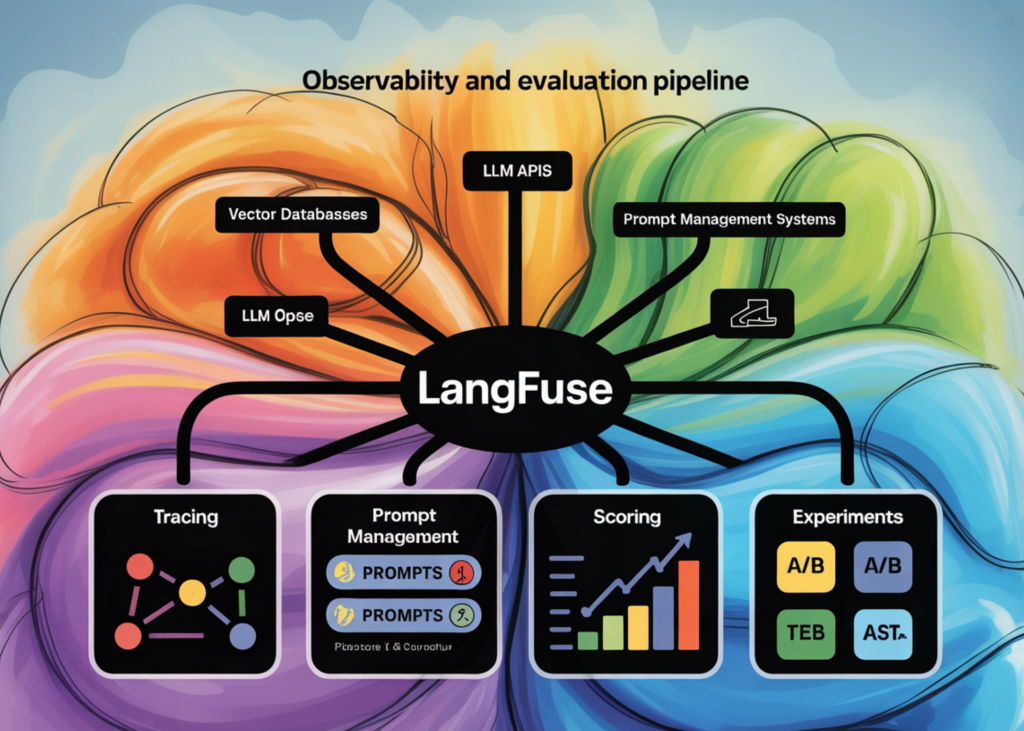
Dans ce tutoriel, nous mettons en œuvre le pipeline Langfuse (une plateforme open source d’ingénierie des grands modèles linguistiques) pour le traçage, la gestion des invites, l’évaluation, les ensembles de informations et les expériences. Nous construisons un flux de travail complet qui fonctionne aussi bien avec une clé OpenAI réelle qu’avec un modèle d’IA linguistique factice déterministe, ce qui nous permet de comprendre toutes les fonctionnalités principales de Langfuse sans avoir besoin d’accéder à des modèles payants. Nous commençons par configurer les identifiants et nous connecter à Langfuse. Nous suivons les appels de fonction simples, instrumentons un petit pipeline RAG, gérons les invites de manière centralisée, associons des notes d’évaluation et menons des expériences basées sur des ensembles de données. Nous voyons également comment Langfuse nous aide à observer, évaluer et améliorer les applications LLM de manière structurée et prête pour la production.
Nous commençons par installer les paquets Langfuse et OpenAI requis dans l’environnement Colab. Nous récupérons ensuite les identifiants Langfuse, choisissons la région Langfuse appropriée ou l’URL d’hébergement autonome, et, si nécessaire, acceptons une clé API OpenAI. Nous initialisons enfin le client Langfuse, vérifions l’authentification et confirmons si nous utilisons OpenAI ou le modèle LLM simulé intégré.
Nous créons un ensemble de données Langfuse consacré aux questions sur les capitales et y ajoutons des items déterministes afin de garantir l’idempotence des exécutions répétées.
Nous définissons l’assistant LLM qui prend en charge à la fois les générations OpenAI réelles et les réponses factices déterministes. Nous veillons également à ce que même le chemin factice génère une observation de génération Langfuse valide, afin que le tutoriel reste entièrement traçable sans clé OpenAI. Nous présentons ensuite un exemple de traçabilité de base basée sur des décorateurs en encapsulant un pipeline simple de génération d’histoires à l’aide de @observe.
Dans le même temps, nous mettons en place un petit pipeline RAG manuel à l’aide d’une base de connaissances simple en mémoire contenant des informations sur les remboursements, les expéditions et les garanties. Nous suivons séparément l’étape de recherche et utilisons la fonction `propagate_attributes` pour associer l’identifiant de l’utilisateur, l’identifiant de session et les balises tout au long de la trace. Nous lançons ensuite une requête relative à un remboursement et enregistrons l’identifiant de la trace afin de pouvoir y associer des scores ultérieurement.
Fait intéressant, nous créons une invite de conversation Langfuse gérée, la compilons avec des variables d’exécution, puis associons cette version de l’invite à une génération de trace. Nous ajoutons ensuite différents types de scores à la trace RAG précédente, notamment des scores numériques, catégoriels et booléens. Nous illustrons également l’évaluation en ligne en notant une réponse concernant une capitale au sein de la portée et de la trace actuellement observées.
Nous créons un ensemble de données Langfuse consacré aux questions sur les capitales et y ajoutons des items déterministes afin de garantir l’idempotence des exécutions répétées. Nous définissons une fonction de tâche qui répond à chaque item, par conséquent que des évaluateurs au niveau des items pour la précision et la longueur des réponses. Nous menons ensuite une expérience sur cet ensemble de données et affichons un résumé formaté des résultats au niveau des items et des résultats agrégés.
Nous présentons également, à titre facultatif, l’intégration de LangChain lorsqu’une clé OpenAI est disponible, en utilisant le gestionnaire de rappel Langfuse pour suivre l’exécution de la chaîne. Si aucune clé OpenAI n’est fournie, nous sautons cette section tout en conservant l’intégralité des fonctionnalités du tutoriel. Enfin, nous transférons tous les événements mis en mémoire tampon vers Langfuse et indiquons où consulter les traces, les invites, les scores et les retombées des expériences sur les ensembles de données.
En conclusion, nous avons mis au point un workflow Langfuse complet et pratique qui couvre les aspects les plus importants de l’observabilité et de l’évaluation des modèles de langage de grande envergure (LLM). Nous avons appris à tracer les opérations automatiques et manuelles, à associer les versions des invites aux générations, à noter les résultats et à évaluer les retombées d’une application à l’aide d’ensembles de données et d’expériences. Nous avons en outre veillé à ce que ce tutoriel reste flexible en prenant en charge à la fois la génération alimentée par OpenAI et un parcours LLM fictif, ce qui facilite le test de l’ensemble du pipeline dans n’importe quel environnement. De plus, nous avons pu comprendre comment Langfuse nous aide à surveiller le comportement des LLM, à comparer les résultats d’expériences et à développer des applications d’IA plus fiables.
Il faudra attendre les retours concrets pour juger de l’impact réel.
À lire également :
- Trump a brusquement annulé la cérémonie de signature du décret présidentiel après que les PDG de grandes entreprises spécialisées dans l’IA ont refusé d’y assister
- Google vient de se positionner comme un acteur majeur dans le domaine de la conception de l’IA lors de l’IO 2026 | TechCrunch
- La prochaine étape du programme « Education for Countries » d’OpenAI
Information rapportée par MarkTechPost : MarkTechPost