Le paysage de l’intelligence artificielle s’enrichit d’une nouveauté significative.
Progression d’un moteur de recherche sémantique et d’un classificateur de statut ouvert sur l’ensemble de données ResearchMath-14k
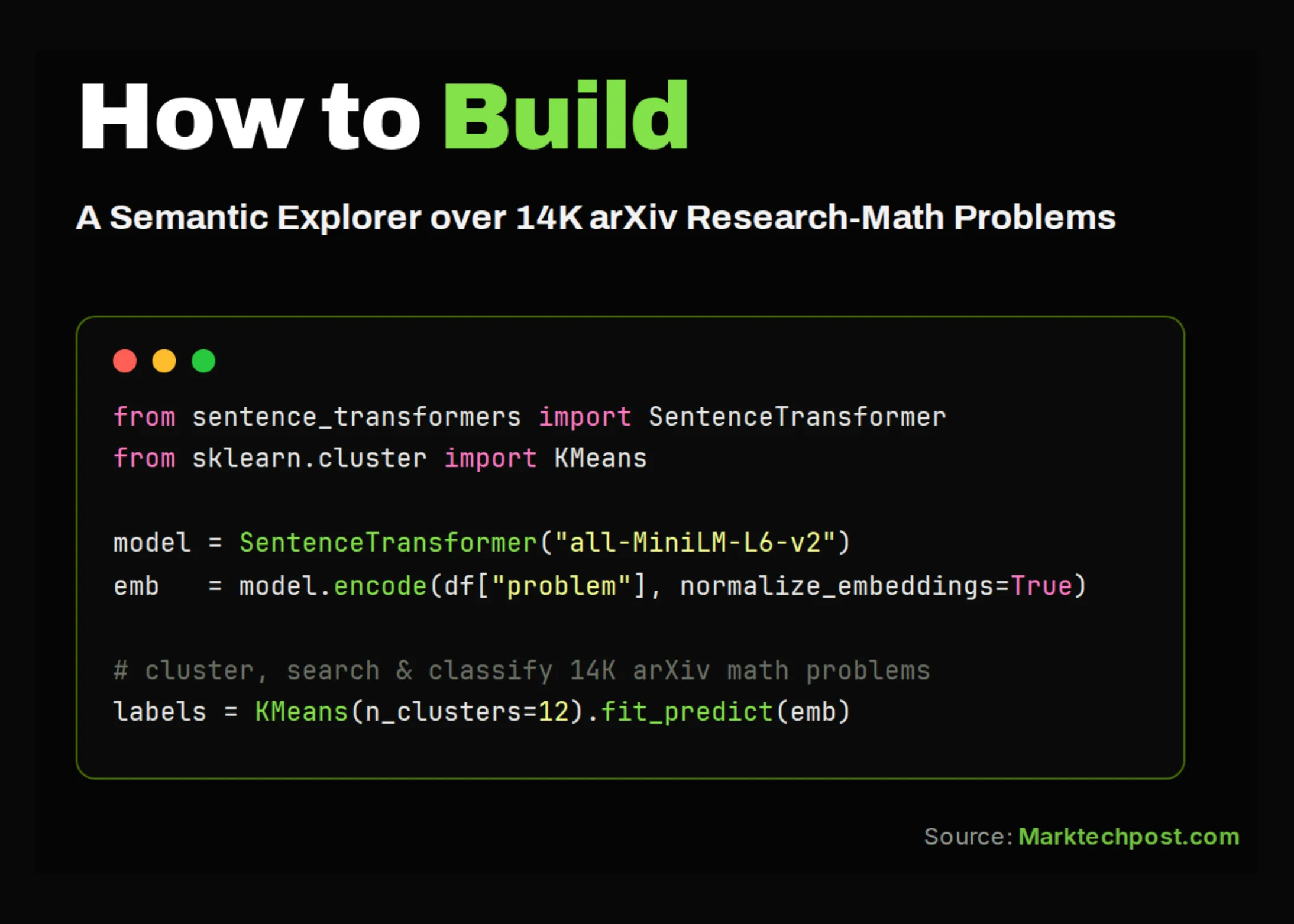
Dans ce tutoriel, nous travaillons avec l’ensemble de données amphora/ResearchMath-14k, une collection de problèmes mathématiques de niveau recherche extraits d’arXiv. Nous chargeons l’ensemble de informations, examinons sa structure et étudions la répartition des problèmes entre les différents domaines mathématiques et les catégories de statut (résolus ou non). Nous allons ensuite au-delà de l’analyse de base en extrayant des mots-clés spécifiques au domaine, en générant des représentations sémantiques, en visualisant l’ensemble des problèmes, en regroupant les problèmes connexes et en créant un moteur de exploration simple sur l’ensemble de informations. De plus, nous entraînons un classificateur afin de prédire le statut d’un problème à partir de ces représentations et de détecter les problèmes étroitement liés ou quasi-duplicatas.
À ce sujet, nous commençons par installer les bibliothèques requises et importer les outils nécessaires à l’analyse, à la visualisation, aux représentations vectoriales et au traitement des données. Nous définissons également les principaux paramètres de configuration, notamment la taille de l’échantillon, la graine aléatoire et le modèle de représentation vectoriale. Cela nous permet de disposer d’une configuration propre avant de commencer à travailler avec l’ensemble de données ResearchMath.
Nous utilisons la méthode TF-IDF pour identifier les termes les plus importants au sein de chaque grand domaine mathématique.
Nous chargeons l’ensemble de éléments amphora/ResearchMath-14k depuis Hugging Face et le convertissons en un DataFrame pandas. Nous examinons le nombre de lignes, les colonnes disponibles et quelques exemples d’enregistrements afin de comprendre la structure de l’ensemble de données. Nous ne conservons ensuite que les énoncés de problèmes d’une longueur suffisante, afin que l’analyse ultérieure porte sur un texte pertinent.
Nous analysons l’ensemble de données en examinant la répartition des problèmes selon leur statut (ouvert ou non) et leur domaine mathématique. Nous visualisons le nombre de problèmes par statut, par domaine et leur longueur afin d’avoir rapidement une vue d’ensemble du corpus. Nous créons également une carte thermique pour observer comment les catégories de statut varient selon les différents secteurs mathématiques.
Nous utilisons la méthode TF-IDF pour identifier les termes les plus importants au sein de chaque grand domaine mathématique. Nous regroupons l’ensemble de données par domaine et extrayons les mots-clés ou expressions les plus significatifs qui caractérisent chaque groupe. Cela nous aide à comprendre quels thèmes et quelle terminologie prédominent dans les différents domaines de recherche en mathématiques.
À noter également, nous échantillonnons l’ensemble de données et convertissons chaque problème mathématique en un encodage sémantique à l’aide d’un modèle SentenceTransformer. Nous réduisons les représentations à deux dimensions à l’aide d’UMAP, ou d’une ACP si UMAP n’est pas disponible, et visualisons le paysage des problèmes par domaine. Nous appliquons ensuite un regroupement par la méthode des K-moyennes et comparons les clusters obtenus à la taxonomie étiquetée par des humains à l’aide des indices ARI et NMI.
En parallèle, nous développons une fonction de travaux de recherche sémantique qui identifie les problèmes de recherche les plus similaires à une requête donnée. Nous entraînons ensuite un classificateur sur les représentations pour prédire si chaque problème est ou non en cours. Enfin, nous calculons la similarité entre tous les problèmes représentés afin de détecter la paire la plus proche et d’identifier les énoncés de problèmes quasi-duplicatas ou étroitement liés.
En conclusion, nous disposons d’un processus complet permettant d’analyser des problèmes mathématiques de niveau recherche à l’aide d’outils modernes de traitement du langage naturel (NLP) et d’apprentissage automatique. Nous avons commencé par explorer l’ensemble de informations, puis nous avons utilisé le TF-IDF, les représentations de phrases, la réduction de dimensionnalité, le regroupement par clusters, la recherche sémantique et la classification pour appréhender la structure du corpus sous différents angles. Cela nous offre un moyen concret d’étudier comment les problèmes mathématiques sont regroupés, comment des problèmes similaires peuvent être identifiés, et comment les représentations peuvent faciliter à la fois l’analyse exploratoire et les tâches de prédiction supervisée.
Les retombées concrètes se feront sentir dans les mois qui viennent.
Pour aller plus loin :
- Comment affiner LFM2 à l’aide de QLoRA et DPO : un didacticiel de codage complet étape par étape sur Google Colab
- Concevoir un pipeline RLVR multimodal complet avec Open-MM-RL, l’utilisation de prompts vision-langage, l’évaluation des récompenses et l’exportation vers GRPO
- Zyphra lance ZAYA1-8B : un modèle de raisonnement MoE formé sur du matériel AMD qui surpasse largement ses concurrents
Information rapportée par MarkTechPost : MarkTechPost